




















ECサイトの顧客分析に役立つクラスター分析とは

Twitterなど各種SNSで、「○○クラスタ」という言葉を見たことがある人もいると思いますが、 今回はそのクラスタの基となった「クラスター」に関しての分析を解説いたします。
クラスター分析とは
そもそも、クラスターの語源は英語の「cluster」を指し、「たくさんの数の集まり」という意味で使われます。 Twitterで見る○○クラスタというのも、共通の○○が好きな人たちの集まりというのが転じ、 「○○ファン」「○○をする人たち」という意味で使われる用になりました。
クラスター分析とは、多くの中から仮説を元に、異なる属性が混在する中から、類似した属性のものを集めてグループを分析する手法です。 このとき大切なのは、前もって分類の基準を決定せず、分類してみて、なぜそのようなグループが作られたかという理由を考える点です。
例えば、酒屋で考えてみましょう。 ・新潟県での売り上げは日本酒が伸びており、 ・山梨県ではワインが伸びていました。 ・男性はビール、女性は梅酒の購入がそれぞれ伸びていました。 これらは、あらかじめ地域性や性別という分類の軸がある中での分類になるため、「クラスター」とは呼びません。
しかし、 ・日本酒がすごく売れている ・ワインがすごく売れている これらを購入している人はどういう人なのかを分類すると ・それぞれ新潟の人が多かった ・山梨の人が多かった という結果がわかりました。
これは、購入データを分類してみた結果、現れたグループごとの特徴となりますので、 「クラスター」となりえます。
また、やたらとビールばかりが売れる日と、ビールがまったく売れない日があり これらを売れる日、売れない日で分けて、購買の理由を分析した結果 ・外気温が30度を超える日は売れる ・それ以下であれば売れない ということがわかりました。 これも「30度を超えた日」というクラスターと「30度以下」というクラスターに分類することができます。
ネットショップ改善提案を聞ける
クラスター分析の手法
クラスター分析には「階層クラスター分析」と「非階層クラスター分析」の2種類があります。
階層クラスター分析とは
階層クラスター分析は、最も似ている組み合わせからまとめていく手法になります。 属性が近いものから順番にグループを作る方法をとり、事前にいくつのグループが作られるかは決める必要がないことが特徴です。 最も似ている組み合わせから順番にグループを作り、グルーピングの途中過程を、下記の樹形図のように表すことができます。
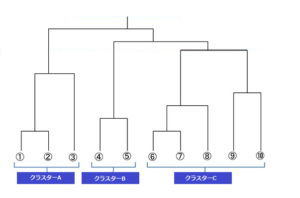
ただ、分類するのではなく、分類の過程でできるグループを確認し、後から分類数を決定できるため、自由度の高い分析を行うことができます。 例えば、上記の樹形図でいえば、クラスターA、B、Cと3つのグループに分類をすることが可能です。 しかし①と②のグループ、③だけのグループ、④と⑤のグループ、⑥と⑦のグループ、⑧だけのグループ、⑨と⑩のグループという少し小さい分類 クラスターA、B、Cを細分化し⑥と⑦と⑧のグループ、⑨と⑩のグループという分類 ①から⑩まですべて独立させたグループとして分類するなど、 自由な分け方が可能となります。
この階層型クラスターの短所は、分類対象が多い場合、樹形図が複雑化し、かえってわかりにくくなってしまう点です。 そのため、分類対象が多い場合は「非階層クラスター分析」を行うのが一般的です。
非階層クラスター分析とは
非階層クラスター分析とは、階層クラスター分析とは違い、事前に何個のグループに分けるかを決める手法の事です。 あらかじめ、分類するグループに分けるかを決め、サンプルを分割する方法である。分類するためのデータが大きいものを分析するときに利用されます。 ただし、あらかじめいくつのグループに分けるかは、分析者が決める必要があり、最適クラスター数を自動的には計算する方法は確立されていません。 いくつか手法はありますが、最も代表的な物に「K-means法」があります。 K-means法の名称は「クラスターの『平均(means)』を用い、事前に決めていたクラスター数『k』個に分類する」ことに由来しています。
この分析の手順は次のようになります。 1:全てのデータから分類するグループの数を決め、グループの基準となるデータを決定数する。(ここでは5個) 2:全てのデータと基準となるデータとの距離を測る。 3:各データを最も近い基準と同じグループに分割する。 4:グループの重心点を決め、それを新たな基準データとする。 5:重心点の位置が変化したら、2に戻り、再度すべての(重心が変化しなくなるまで繰り返す) 6:重心が変化したので、再度全てのデータ個の数と基データの距離を測る。 7:各サンプルを最も近いデータと同じグループに分割する 8:重心が変化しなくなったので終了する。
もう少し具体的にみてみましょう。 まず、何個のグループに分類していくかを決めます。このとき決定したグループの数は以下K個とします。

次に、その分類するグループの基データを、K個選びます。 今回はこの赤、黄、青、緑、紫のものを基のデータとします。

すべてのデータを、選ばれたK個の基データと最も近いものと紐付けをします。 同色同士が基データで近いもの同士の紐付けをされたものになります。
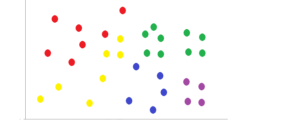
すると、全データは基になっているK個のデータと、それぞれ最も位置の近いものと紐付けがされたグループが完成します。
今度はこのK個のグループ内で最も平均的なものを、それぞれ基データとして選びます。 なぜなら、この最初のも基準としているデータは、あくまで主観で選んだものになるため、数的根拠がないからです。 そのため、再度作ったグループの中で中心に来るあるものを基データとしてピックアップし、グループを選びなおします。
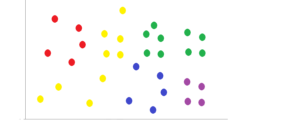
これを繰り返し、最も平均値な位置づけとして分類できるようになったら終了となります。
問題点
k-means法の一つの短所として、最初に選ぶ基データに依存してしまうところにあります。 重心が変化しなくなるまで計算をしても、最初の基データが異なるだけで、結果が大きく違ってきます。 そのため、初期の基データを変えて何回か分析を実施していくことが大切です。
まとめ
クラスター分析はデータをクラスターというグループに分類し分析する手法です。 あらかじめいくつのグループに分類するかを決めていない「階層クラスター分析」 反対に、いくつのグループに分類するかを決めている「非階層クラスター分析」 の2種類があります。
どちらも基データを特定の切り口で分類し、近い結果同士でグループを作り分析をしていく方法です。 「階層クラスター分析」は、分析データ数が少ないときに 「非階層クラスター分析」は、分析データ数が多いときに それぞれ相性がいい分析手法となります。
では、次回はこれをECサイトで有効に利用する方法を解説いたします。
ネットショップ改善提案を聞ける

関連記事
-
 2024/09/30(月)
2024/09/30(月) -
 2024/09/30(月)
2024/09/30(月) -
 2024/09/26(木)
2024/09/26(木) -
 2024/09/24(火)
2024/09/24(火) -
 2024/09/13(金)
2024/09/13(金)